
Microsoft Research heeft zojuist zijn eigen versie van een heavy metal kwartet laten vallen, tools die de toekomst van AI compilatie zullen aandrijven.
Deze vier AI-compilers, met de toepasselijke bijnamen “Roller”, “Welder”, “Grinder” en “Rammer”, zijn van plan om de manier waarop we denken over rekenefficiëntie, geheugengebruik en controlestroom binnen AI-modellen te herdefiniëren.
AI-tools versnellen compilatietijden drastisch
Roller, de eerste van deze tools, wil de status quo van het compileren van AI-modellen, dat vaak dagen of weken in beslag neemt, doorbreken. Het systeem stelt het proces van datapartitionering binnen versnellers opnieuw voor. Roller functioneert als een wals, die nauwgezet hoogdimensionale tensorgegevens op tweedimensionaal geheugen plaatst, vergelijkbaar met het betegelen van een vloer.
Wil je meer weten over Microsofts AI-chatbot Bing? Klik hier.
De compiler zorgt voor een snellere compilatie met een goede rekenefficiëntie, waarbij de focus ligt op hoe het beschikbare geheugen het beste kan worden gebruikt. Uit recente evaluaties blijkt dat Roller binnen enkele seconden sterk geoptimaliseerde kernels kan genereren, waarmee hij bestaande compilers met drie orden van grootte overtreft.
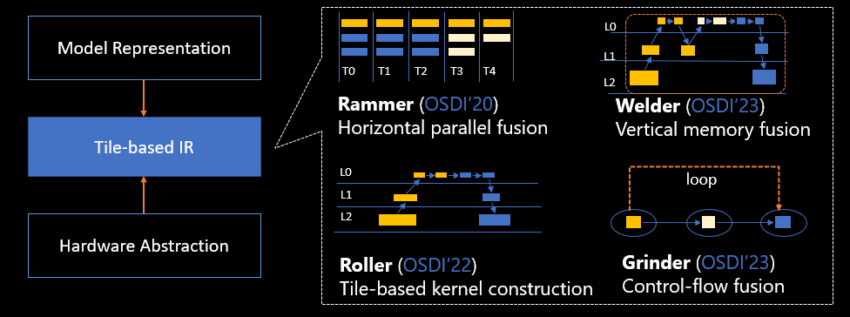
Welder richt zich op het geheugenefficiëntieprobleem dat inherent is aan moderne DNN-modellen(Deep Neural Network). De compiler is ontworpen om de slechte afstemming tussen het gebruik van rekenkernen en de verzadigde geheugenbandbreedte te verhelpen.
Door gebruik te maken van een techniek analoog aan lopende band productie, “last” Welder verschillende stadia van het rekenproces aan elkaar. Dit vermindert onnodige gegevensoverdrachten en verbetert de efficiëntie van geheugentoegang aanzienlijk.
Tests op NVIDIA en AMD GPU’s geven aan dat de prestaties van Welder mainstream frameworks overtreffen, met snelheden die 21,4 keer hoger liggen dan die van PyTorch.
Grinder versnelt processen met 8x
Grinder richt zich op een ander cruciaal aspect – efficiënte uitvoering van besturingsstromen. In lekentaal: het heeft als doel om AI-modellen slimmer te maken in het bepalen wat wanneer moet worden uitgevoerd. Door besturingsstromen te “vermalen” tot gegevensstromen, verbetert Grinder de algehele efficiëntie van modellen met complexere besluitvormingstrajecten.
Wil je productiever worden? Ons Learn-team geeft hier een overzicht van de 18 beste tools.
Experimentele gegevens tonen aan dat Grinder tot 8,2x sneller is op DNN-modellen met een intensieve controlestroom, waarmee bestaande frameworks worden overtroffen.
Tot slot werkt Rammer aan het maximaliseren van hardware parallellisme. Dit verwijst naar de capaciteit van hardware om verschillende dingen tegelijkertijd te doen.
Dit zwaar metalen kwartet van Microsoft AI-compilers is gebouwd op een gemeenschappelijke abstractie en uniforme tussenliggende representatie, en vormt een uitgebreide set oplossingen voor het aanpakken van parallellisme, compilatie-efficiëntie, geheugen en controlestroom.
Jilong Xue, hoofdonderzoeker bij Microsoft Research Asia, zei:
“De AI-compilers die we hebben ontwikkeld hebben een substantiële verbetering laten zien in AI-compilatie-efficiëntie, waardoor het trainen en inzetten van AI-modellen wordt vergemakkelijkt.”
Disclaimer
Disclaimer
Alle informatie op onze website wordt te goeder trouw en uitsluitend voor algemene informatiedoeleinden gepubliceerd. Elke actie die de lezer onderneemt op basis van de informatie op onze website is strikt op eigen risico.
